n折交叉验证数据分割
KFold
首先看官网对这个类的定义(括号中均为默认参数)
1 | class sklearn.model_selection.KFold(n_splits=5, *, shuffle=False, random_state=None) |
KFold返回的是索引,共有三个参数:
n_splits,n折交叉验证,作者一般取10。
shuffle,洗牌的意思。若shuffle=False,则返回的测试集索引连续且固定。比如我们有50个样本,若采用十折交叉验证,则返回的测试集索引依次为,0-4,5-9……,代码实例于下:
1 | from sklearn.model_selection import KFold,StratifiedKFold,RepeatedKFold |

(后续为了解释方便将不打印出训练集系数)
若shuffle=True,则返回的测试集索引随机且不连续。仍以50个样本为例,若采用十折交叉验证,代码实例于下:
1 | from sklearn.model_selection import KFold,StratifiedKFold,RepeatedKFold |
第一次运行结果:

第二次运行结果:
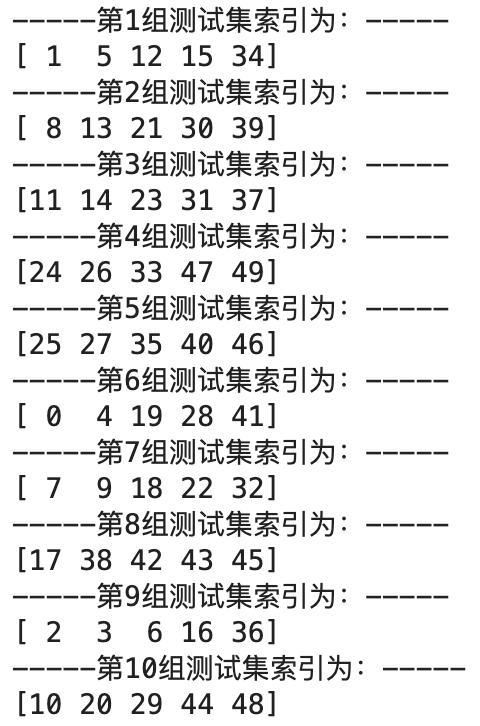
可以看出当参数shuffle=True,每次返回的索引值都不同。
random_state:在shuffle=False时没有意义。在shuffle=True时,设置成一个数字会使每次生成的随机数字相同,还以之前的50个样本的数据集为例:
1 | from sklearn.model_selection import KFold,StratifiedKFold,RepeatedKFold |
第一次运行结果:

第二次运行结果:
StratifiedKFold
1 | class sklearn.model_selection.StratifiedKFold(n_splits=5, *, shuffle=False, random_state=None) |
参数与KFold中的参数相同,唯一不同是“The folds are made by preserving the percentage of samples for each class.” 即划分后的训练集和验证集中类别分布尽量和原数据集一样。
1 | from sklearn.model_selection import KFold |

RepeatedKFold
1 | class sklearn.model_selection.RepeatedKFold(*, n_splits=5, n_repeats=10, random_state=None) |
生成的一定是随机的,只不过是加了重复的次数