1 | from sklearn.metrics import r2_score |
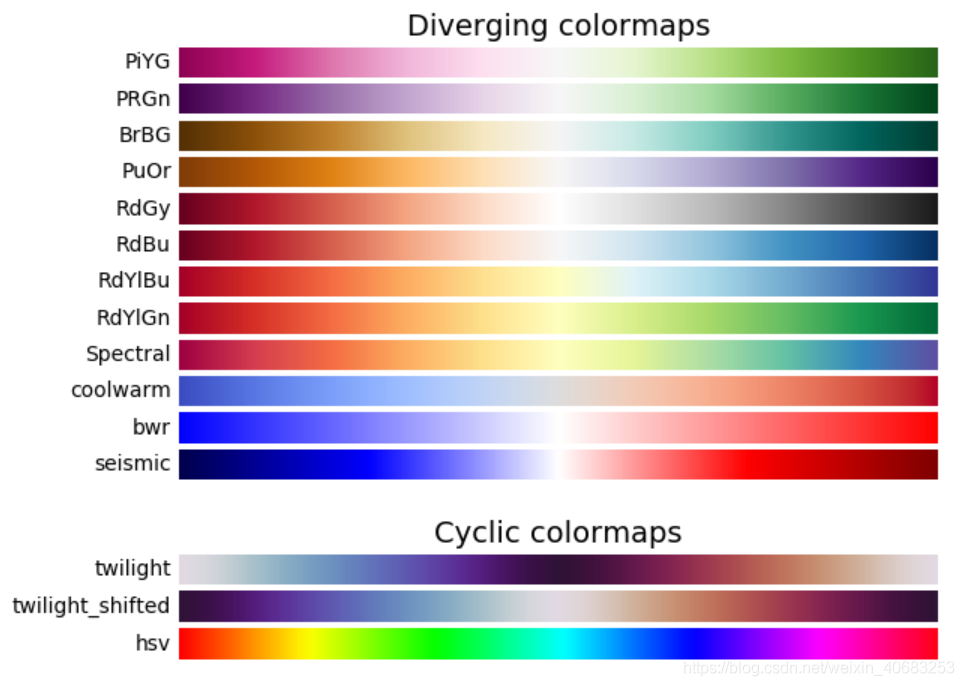
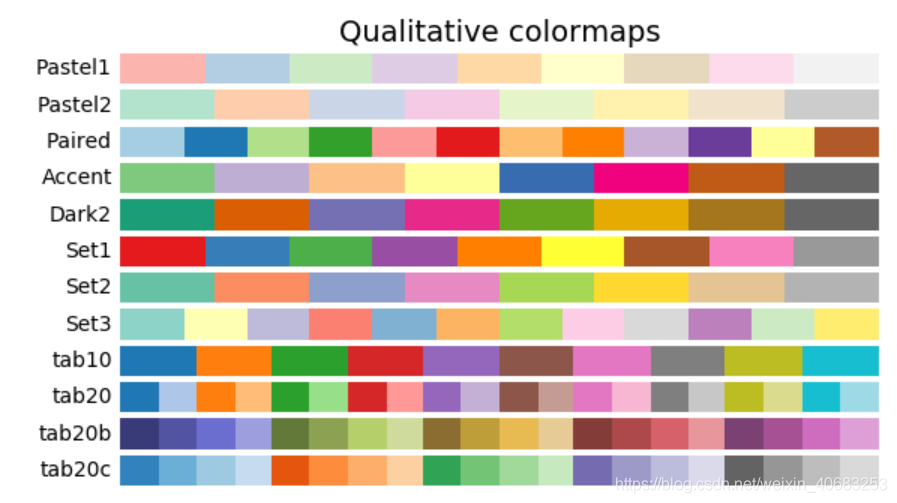
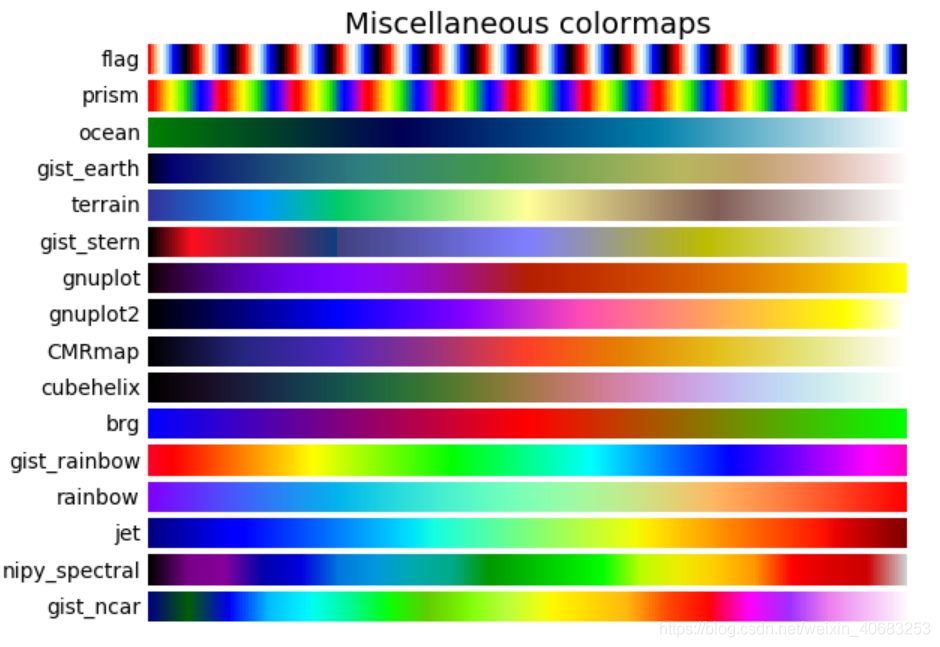
python画图配色
双电层的建立
双电层建立的GCS模型
财务报销三步
LDA+U
加U体系
zotero快速复制引文
zetero技巧
过渡态计算
过渡态计算
华为20200819电池组面试
上传几道陈荣汉的考试题
VASP中的赝势
综述关系
1 | graph LR |
This work is based on the density functional theory (DFT) calculations performed by using the Vienna ab initio Simulation Package (VASP) software. The interaction between ion cores and valence electrons described by the projector augmented wave (PAW) method34. The generalized gradient approximation (GGA)35 in the form of Perdew–Burke–Ernzerhof (PBE) exchange functional36 was used to solve the quantum states of electron. The plane-wave energy cutoff is set to 500 eV. The Monkhorst–Pack method37 with 1 × 1 × 2 k-point mesh is employed for the Brillouin zone sampling of the super lattice. The convergence criteria of energy and force are set to 10−5 eV/atom and 0.01 eV/Å, respectively. The anion charges of lithium compounds were calculated by using the Atoms in Molecules method (Bader charge analysis)38. The energy variations and migration barriers of lithium ion migration in fcc-type anion sublattices with 48 anions (Supplementary Fig. 3) are calculated by the nudged elastic band (NEB) method39,40. The anion charges are changed by the uniform background charge of the sublattice system. Only the one migrating lithium ion is allowed to relax, while the other anions are fixed in their initial positions, and this method can be also found in Ceder’s work8 .
文章中引用的时候需要五篇:DFT,PAW,GGA,PBE,VASP
详细介绍
vasp计算中用到的三种赝势:模守恒赝势,超软赝势,PAW赝势(按产生顺序)。
按方法不同分为USPP(ultrasoft pesudopotential,超软赝势)和PAW(projector augmented wave,投影缀加平面波),两种方法都可以相当程度地减少过渡金属或第一行元素的每个原子所必需的平面波数量。
按交换关联函数不同分为LDA(local density approximation,局域密度近似)和GGA(generalized-gradient approximation,广义梯度近似),GGA又分为PW91(Perdew -Wang 91)和PBE(Perdew-Burke-Ernzerhof)。
求解K-S方程时电子之间的交换关联泛函取局域密度泛函LDA(Rc处电子结构当成是密度相同的均匀电子气体来算)。
广义梯度泛函GGA(考虑了密度的梯度变化),但泛函的不同也会引起贋势的不同。
- paw文件夹:PAW-LDA
- paw_gga文件夹:PAW-GGA-PW91
- paw_pbe文件夹:PAW-GGA-PBE
- pot文件夹:USPP-LDA
- pot_GGA文件夹:USPP-GGA
选择某个目录进去,我们还会发现对应每种元素往往还会有多种赝势存在。这是因为根据ENMAX的大小还可以分为 Ga,Ga_s(soft),Ga_h,或者根据处理半芯态的不同还可以分为Ga,Ga_sv(s电子作为半芯态),Ga_pv的不同。
对于化合物(不同原子半径的元素混合)来说,PAW赝势比超软赝势精确度高。
US型赝势所需截至能较小,计算速度快,PAW赝势截至能通常较大,而且考虑的电子数多,计算慢,但精确度高。
在做具体的计算之前,针对需要计算的性质选取不同的贋势做下测试。对于不同贋势得到的结果,关注其最终的能量差,而不是绝对能量。
顺时针打印矩阵(剑指offer29)
题目要求
输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字。
1 | 示例 1: |
源代码
1 | class Solution: |
知识点
While True的作用
range函数
range函数有三个参数range(start, stop[, step]), 一般来说range函数默认从0开始,第一额参数显示,最后一个参数不显示,若步长为-1则需要start大于stop
类和函数的区别及调用,self的作用
1 | matirix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]] |